¶
![]()
YDF is a library to train, evaluate, interpret, and
serve Random Forest,
Gradient Boosted Decision Trees, and CART decision forest models.
Gradient Boosted Decision Trees, and CART decision forest models.
A concise and modern API
YDF allows for rapid prototyping and development while minimizing risk of modeling errors.


Deep learning composition
Integrated with Jax, TensorFlow, and Keras.
Cutting-edge algorithms
Include the latest decision forest research to ensure maximum performance.
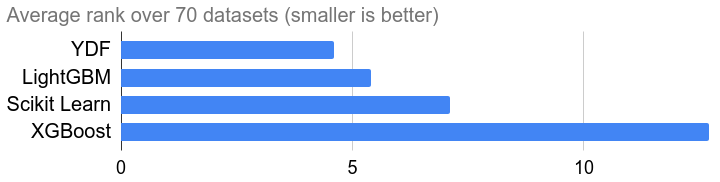
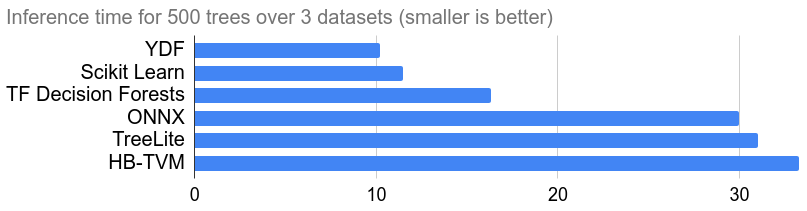
Fast inference
Compute predictions in a few microseconds. Executed in the tens of millions of times per second in Google.
Installation¶
To install YDF from PyPI, run:
YDF is available on Python 3.8, 3.9, 3.10, 3.11 and 3.12, on Windows x86-64 Linux x86-64, and macOS ARM64.
Usage example¶
![]()
import ydf
import pandas as pd
# Load dataset with Pandas
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset/"
train_ds = pd.read_csv(ds_path + "adult_train.csv")
test_ds = pd.read_csv(ds_path + "adult_test.csv")
# Train a Gradient Boosted Trees model
model = ydf.GradientBoostedTreesLearner(label="income").train(train_ds)
# Look at a model (input features, training logs, structure, etc.)
model.describe()
# Evaluate a model (e.g. roc, accuracy, confusion matrix, confidence intervals)
model.evaluate(test_ds)
# Generate predictions
model.predict(test_ds)
# Analyse a model (e.g. partial dependence plot, variable importance)
model.analyze(test_ds)
# Benchmark the inference speed of a model
model.benchmark(test_ds)
# Save the model
model.save("/tmp/my_model")
Key features¶
Modeling
- Train Random Forest, Gradient Boosted Trees, Cart, and Isolation Forest models.
- Train classification, regression, ranking, uplifting, and anomaly detection models.
- Plot of decision trees.
- Interpret model (variable importances, partial dependence plots, conditional dependence plots).
- Interpret predictions (counter factual, feature variation).
- Evaluate models (accuracy, AUC, ROC plots, RMSE, confidence intervals, cross-validation).
- Hyper-parameter tune models.
- Consume natively numerical, categorical, boolean, tags, text, and missing values.
- Consume natively Pandas Dataframe, Numpy Arrays, TensorFlow Datasets, CSV files and TensorFlow Records.
Serving
- Benchmark model inference.
- Run models in Python, C++, Go, JavaScript, and CLI.
- Online inference with REST API with TensorFlow Serving and Vertex AI.
Advanced modeling
- Compose YDF models with Neural Network models in TensorFlow, Keras, and JAX.
- Distributed training over billions of examples and hundreds of machines.
- Use cutting-edge learning algorithm such as oblique splits, honest trees, hessian scores, global tree optimizations, optimal categorical splits, categorical-set inputs, dart, extremely randomized trees.
- Apply monotonic constraints.
- Consumes multi-dimensional features.
- Enjoy backward compatibility for model and learners since 2018.
- Edits trees in Python.
- Define custom loss in Python.
Next steps¶
Read the 🧭 Getting Started tutorial. You will learn how to train a model, interpret it, evaluate it, generate predictions, benchmark its speed, and export it for serving.
Ask us questions on Github. Googlers can join the internal YDF Chat.
Read the TF-DF to YDF Migration guide to convert a TensorFlow Decision Forests pipeline into a YDF pipeline.